1、前言
最近刚开始用Flink做流计算,踩了个坑,根据以往做实时流计算的经验,捋了一下Flink与Storm、Spark Streaming 的区别之后最终成功定位到问题并解决了。先不说坑在哪里,先说bug的表现:
- 数据处理出结果的时间与数据自带的EventTime相差了十几秒;
- 数据进入时候的延时为0~1秒;
- 数据处理时间据log打印为50~200毫秒;
- 数据入库花费时间约为300~700毫秒;
- 设置了窗口间隔为1秒;
- 设置了水印为流过数据的EventTime中最大的时间,允许乱序时间为1秒;
是不是很奇怪?明明数据延时加上数据处理和入库的时间,也不过2~3秒,为什么最终结果数据却和数据本身的EventTime相差10多秒?
附上水印生成的相关代码:
1 | import com.xiaobi.model.MiniCourse; |
确认日志给出的处理时间无误后,对比Flink和我以前用过的流处理框架,唯一不一样的地方,就是Flink独有的新概念——水印了,那是不是水印的锅呢?我们先来看看Flink的水印是什么。
2、Flink的水印
在讲水印之前,我们先复习一下几个关于时间的概念:
- EventTime:事件时间,事件发生的事件,通常是用户行为发生的最准确的事件。
- IngestionTime:注入时间,事件注入到 Flink 框架的事件,是在 source 算子执行的时候生成的事件,通常是在 jobManager 服务器的系统时间。
- ProcessTime:处理时间,事件处理的时间,通常是在 transform 过程中生成的时间戳,在 taskManager 机器生成。
实际上其实也就2类,一类是数据自带的时间,一类是系统生成的时间。
而在实时流处理中,为了更准确的反应用户行为分析结果,我们经常会采用数据发生的时间:*EventTime * 作为数据处理的的时间戳。然而,网络问题或者其他问题都有可能会引起数据的延时到来,如果按照 EventTime 去做处理,我们不得不等待数据齐备,或者抛弃掉延时的数据,最终很可能得不到我们预期的结果。为了解决这种数据延时的问题,Flink 中引入了 Watermark 水印去处理这种特殊情况。
水印是什么?
Watermark 的直译为水印,他其实是数据进入flink之后,附加到数据上面的一个隐藏属性,每个水印都携带有一个时间戳。当时间戳为T的水印出现时,表示事件时间t <= T的数据都已经到达,即水印后面只应该流入事件时间t > T的数据。也即是说,它存在的意义,其实是为了告诉Flink判断迟到数据的标准,同时也是窗口触发的标记。
水印的生成
水印的生成相当灵活,但是大部分的设计都如前言提到的水印生成代码一般,有一个固定可配置的最大乱序时间,然后数据流进来的时候,根据数据自带的EventTime计算出一个水印:
1 | public Watermark getCurrentWatermark() { |
先不看减去的那个最大允许乱序时间,这里缓存流经数据里面的最大值来作为水印生成的时间戳,也正是水印本身的任务:标记在该水印前的数据已经到达。试想一下,假设数据是顺序到来的,如(1,2,3,4,5)这样的数据流,当5到达的时候,生成的水印w(5),是不是确实标志着5之前的数据已经到达了?
顺序的数据没啥问题了,那乱序的数据呢?水印的存在正是为了解决流计算乱序(out-of-order)问题的
以水印解决流处理的数据乱序问题
要说解决流处理过程中的数据乱序问题,可以说所有的流计算框架都只有一种办法——那就是等。。。先假设有数据流(1,2,4,3,5),我们程序需要每4秒触发一次计算,假如按照当前数据流,当第三个数据“4”到来的时候,生成的水印为w(4),Flink一看w(4)都到了,也就是4秒前的数据全到了,可以触发计算了,然后一算发现结果不对!为什么呢?因为“3”还在后面没到呢。。。等3到了1~4秒的窗口早算完了。
要解决这种乱序问题,我们只能告诉Flink,我们需要等“3”到了再开始计算啊,而告诉Flink的方法,就是设置最大允许乱序时间,也就是上述代码中的maxOutOfOrderness。这个设置其实就是一个生成水印的小技巧:通过以当前最大时间减去允许乱序时间来形成一条比实际时间要大的水位线,来等待迟到的数据。
这么说有点晕,我们还是以数据流(1,2,4,3,5)来看,假设设置最大运算乱序时间为1秒,当第三个数据“4”到来的时候,生成的水印为w(4 - 1),也就是w(3),而窗口的触发为需要至少w(4)到达,所以窗口不触发,继续等待下一个数据;然后下一个数据”3”到来,生成的数据也是w(3),不变,继续等待;再下一个数据”5”到来,生成水印为w(4)触发计算,那么1~4秒的窗口数据就全部到到齐了。
更直观来看,通过对数据生成一个比实际时间少的水印,来达到了延时等待的效果,最大允许乱序时间其实就是数据延时等待时间,4秒触发的窗口,其实要等第5秒的数据达到才能触发,其实就是变相地在窗口触发的时间之上设计了一条水位线。
3、问题的缘由
其实介绍完Flink的水印之后,好像问题出在哪也有点眉目了,上面提到说,水印的作用不仅仅是解决乱序问题,同样也是触发窗口计算的条件。在观察数据之后,发现接入的datahub数据的频率并不是很高,所以当时我就怀疑,是不是数据没有持续流入,导致最后一小批数据进入之后,一直在等待能触发窗口计算的水印到达呢?
为此我写了一个测试代码:
1 | public class testWatermark { |
代码挺简单的,读取datahub的topic的作为数据源,然后就是4个算子:
- flatMap处理成Tuple2<String,Long>;
- assignTimestampsAndWatermarks 对数据生成水印;
- timeWindowAll设置窗口间隔;
- apply触发窗口计算
然后导入到Datahub的实验数据:
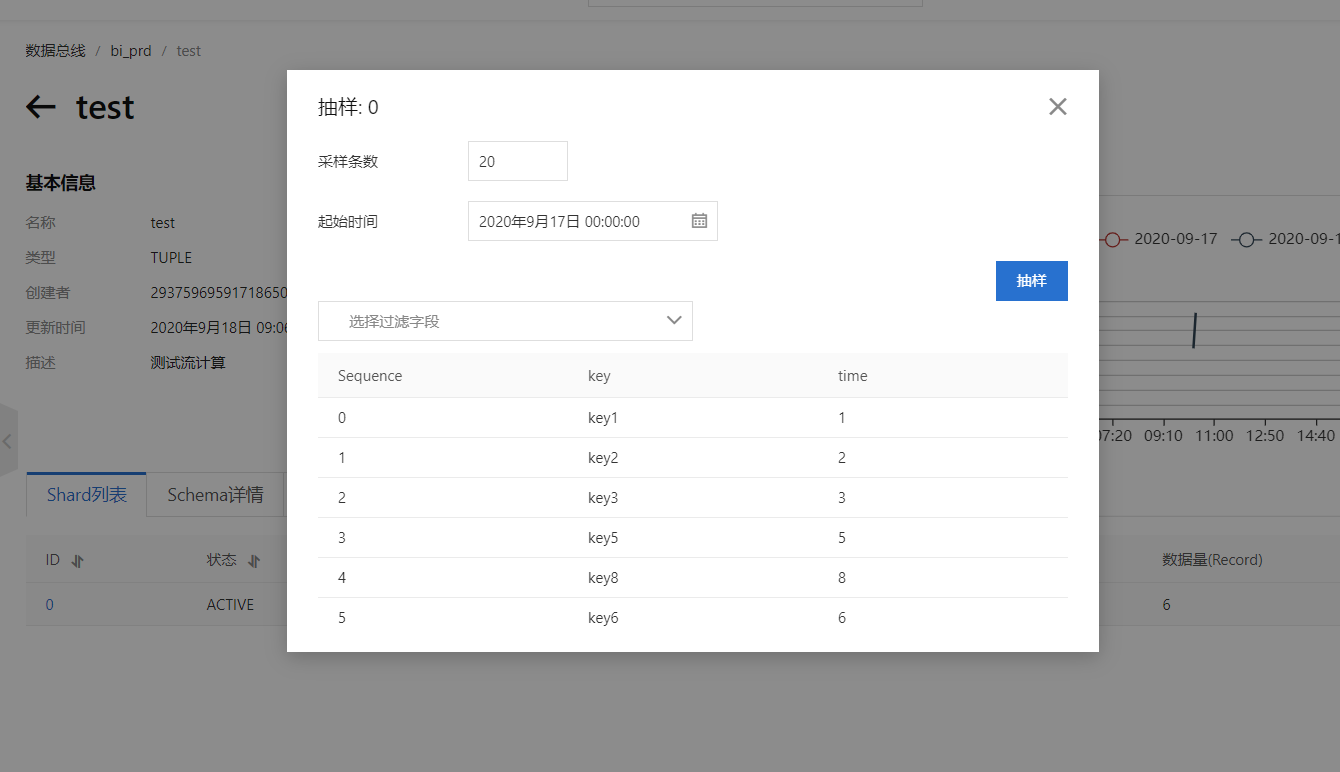
这里少了一个4,未运行之前我们先来猜一猜运行结果:因为设置窗口时间为4秒,最大允许乱序时间为1秒,所以实际触发窗口计算的水位线为第五秒数据到来。所以理论是当key5到来时,触发窗口,计算得出14秒窗口最大数据就是3秒;而58窗口,实际触发窗口计算的水位线应该是第9秒,就是说如果后续没有数据进去datahub,这个窗口就会无限等待。。
整个数据水印过程,我画了一下,方便理解流程:
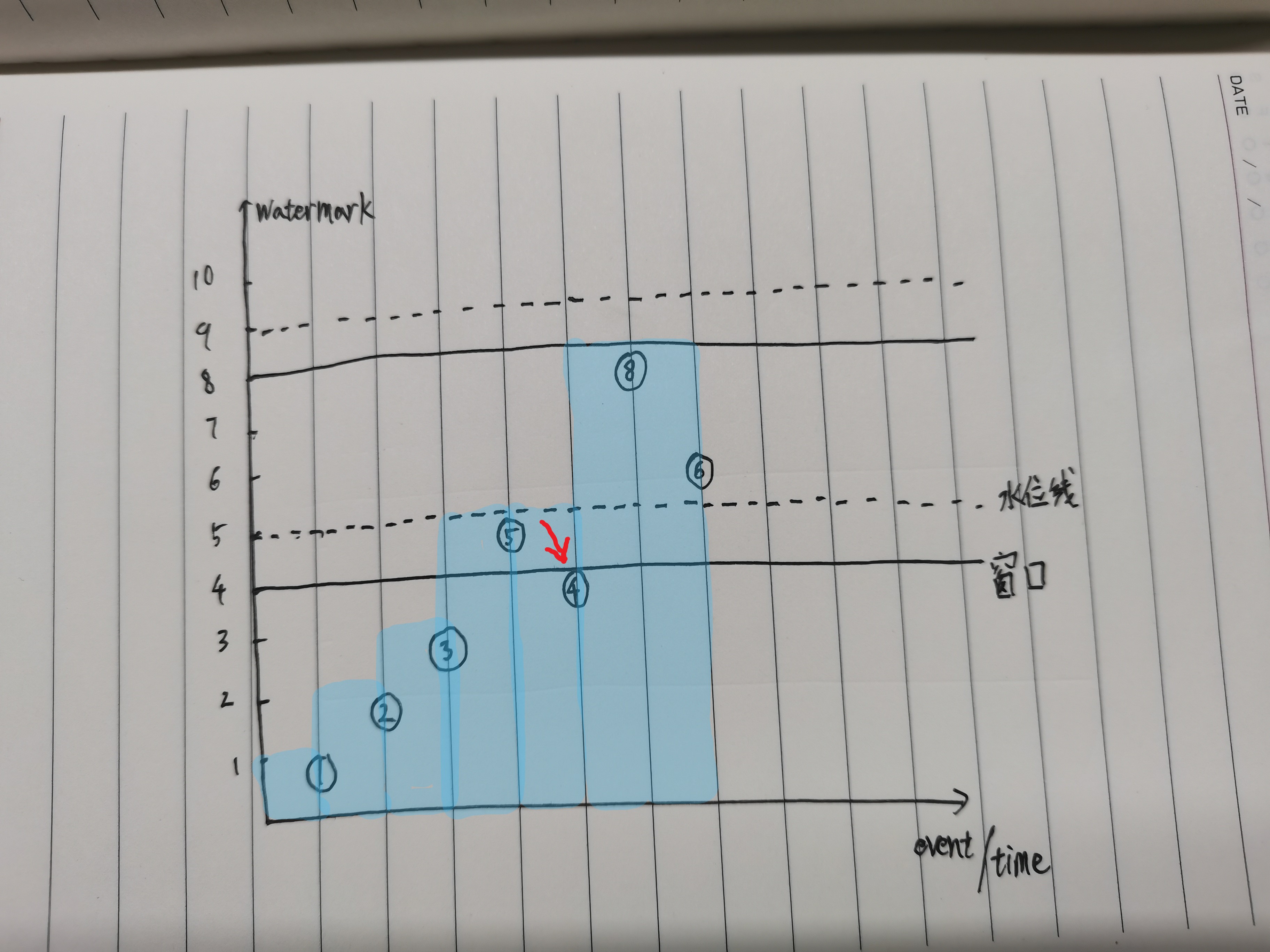
数据里面没有4,假如有4在5后到达的话,实际上会被当延迟数据给抛弃的。
然后我们来运行一下代码,得出日志如下:
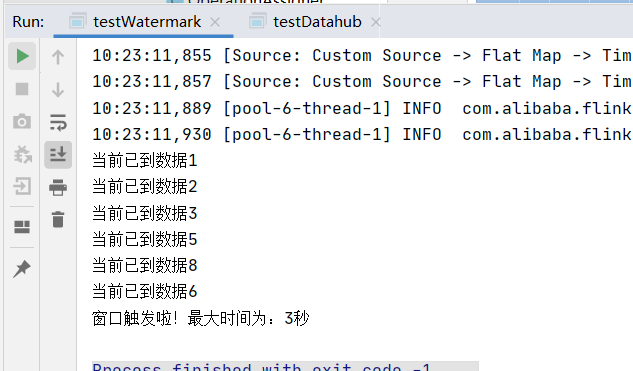
和预想的完全一致,实际上我那个实时计算的项目,通过别的手段解决掉数据乱序带来的影响之后,取消了水印,使用TimeCharacteristic.ProcessingTime来开窗之后,数据延时就正常了。
总结一下:就是如果是读取实时流(测试时候用过fromCollection读完数据就会触发最后一个窗口)要注意,如果数据频率不高,很有可能会造成最后一部分数据因为等待数据而被延时计算,如果需要保证有序,则应该再去设置一个等待延时数据的时间,超时直接触发计算窗口。
4、关于延时数据等待的一些心得
做实时计算很多情况下其实都需要保证数据有序的,在以前做交通大数据项目的时候,有要求数据有序以及齐备,又要求较高的实时性,所以说像Flink这样,固定设计几秒是完全不行的。以实时路段速度计算为例,卡口数据在时间间隔内需要尽可能等待齐全,而实际全市的设备网络延迟不一致,有时候数据会延时1秒,有时候数据会延时2秒,每天都不一样。如果像Flink这样固定1秒延时等待,那数据可能会漏,如果固定2秒延时,那计算就达不到尽可能的实时。
面对这种情况,我当时对于延时等待时间,其实也是实时计算的。当时用的是storm,窗口间隔以及触发条件全都是自己代码实现的,虽然麻烦但是也给了我很大的灵活处理空间。观察数据之后发现了一个细节,虽然每个设备过来的数据都不一样,但是数据的延时情况整体来说还是呈正态分布的:假设数据有100条,延时100毫秒的有10条,延时200毫秒内的有60条,延时300毫秒的有20条,剩下10条都在300毫秒之后。
这样我就可以利用这个规律来设计延时等待。开窗计算5秒的数据,当5秒到达时,开始做动态延时:
1、延迟100毫秒,100毫秒后计算,这0~100毫秒内进入数据的数据里面,延时数据的占比;
2、如果延时数据占比高于阈值(设置为5%),往后延时100毫秒,执行步骤一
3、当延时数据占比低于阈值时,说面后续可能到达的延时数据已经相当小了,此时触发这个5秒窗口的计算
这样做的话,经过生产环境的验证,面对偶尔的全市高延时,实时计算依然能等待到足够的数据得出可靠的计算结果;而平时低延时的时候,也可以最快地收集齐数据得出结果
Flink其实也可以相当地灵活,如果未来有面对这种场景的时候,也不妨可以放弃Flink预设的窗口,把Flink当作Storm来用。