1、起因
某天java组的同事跟我说,es查询报错了,报了个Data too large异常,网上找了一下,好像这个内存不足是es默认设置引起的,具体的再分析看看。
详细的报错信息如下:
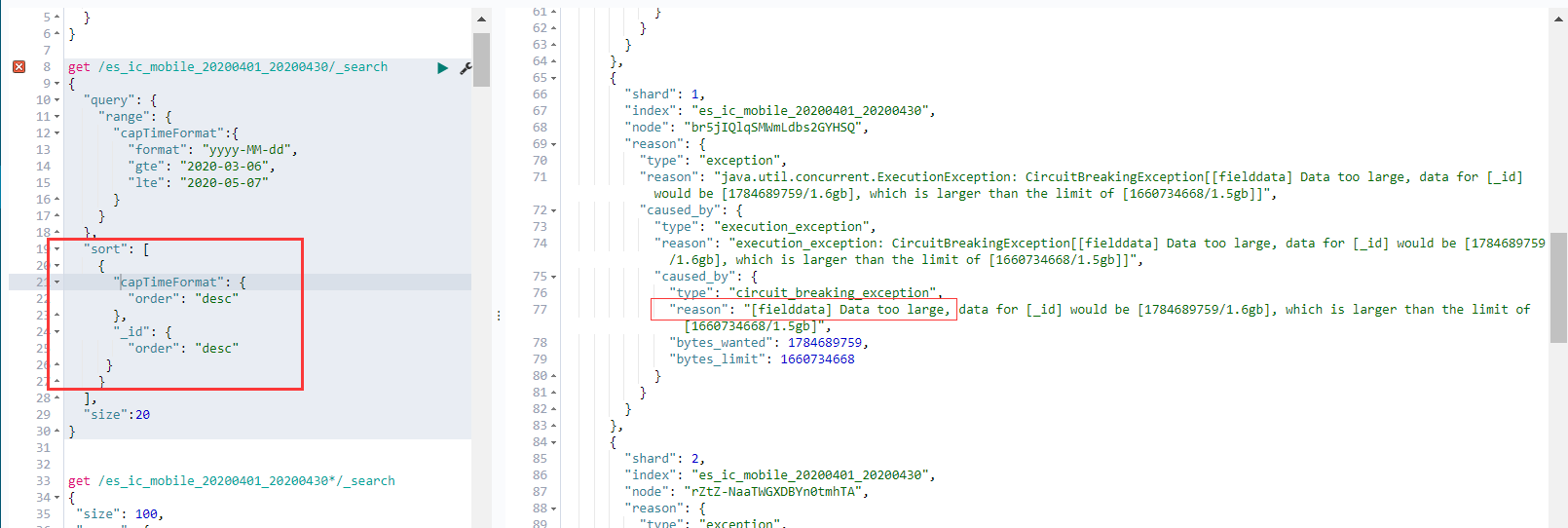
查询的json:
1 | get /es_ic_mobile_20200401_20200430/_search |
2、内存不足是怎么引起的?
官方文档关于这个问题有很详细的解释: 限制内存使用
设想我们正在对日志进行索引,每天使用一个新的索引。通常我们只对过去一两天的数据感兴趣,尽管我们会保留老的索引,但我们很少需要查询它们。不过如果采用默认设置,旧索引的 fielddata 永远不会从缓存中回收! fieldata 会保持增长直到 fielddata 发生断熔(请参阅 断路器),这样我们就无法载入更多的 fielddata。
显然,我们在装好华为集群的时候就没改过es的设置,用的设置也就是默认设置了,所以当缓存容量达到了熔断器的阈值的时候,每一次需要加载数据到内存的操作,都会因为触发熔断而直接返回报错:[FIELDDATA] Data too large, data for [proccessDate] would be larger than limit of [10307921510/9.5gb]]
网上找了个图更好理解:
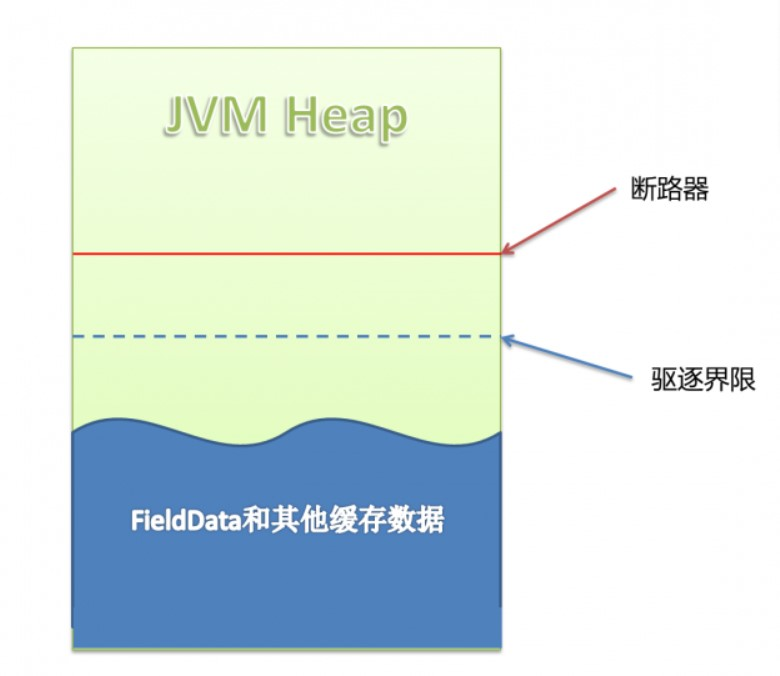
而如果使用默认参数,就是相当于断路器那条红线跟驱逐界限那条蓝线重叠,这就意味着,永远不会触发回收,因为内存累积满了之后下一次查询会直接触发熔断,然后内存里面的数据也不会有变化。
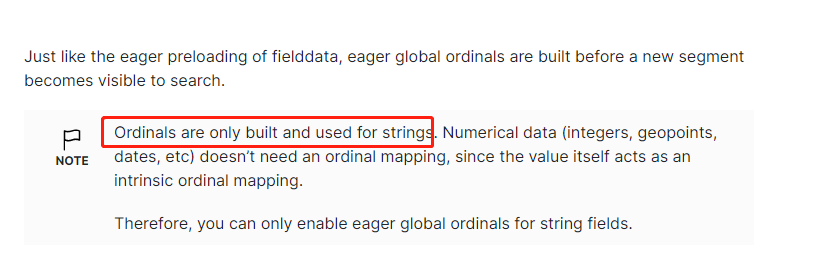
值得注意的是:es的fielddata只会针对string类型数据做缓存,long、int、date等数据皆不会缓存起来。
3、解决办法
官网也很贴心的给了出来:
为了防止发生这样的事情,可以通过在
config/elasticsearch.yml文件中增加配置为 fielddata 设置一个上限:
indices.fielddata.cache.size: 20%( ps:可以设置堆大小的百分比,也可以是某个值,例如: 5gb 。)有了这个设置,最久未使用(LRU)的 fielddata 会被回收为新数据腾出空间。
在华为集群中,我看了下,只有indices.breaker.fielddata.limit这个参数
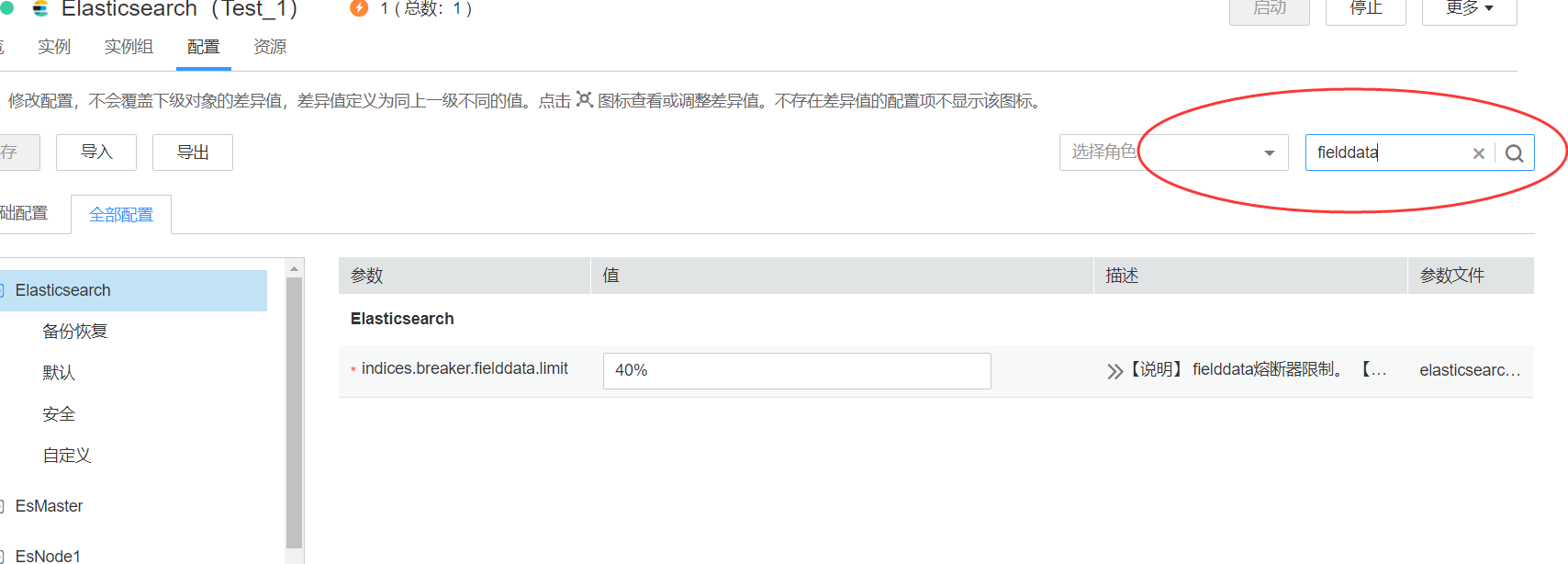
然后官网也说是新增配置,考虑到熔断器设置在40%,所以缓存大小设置到20%或者30%就好了,目标就是让他不至于一次性查询就触发熔断。当然最好还是要用大内存的。
4、为什么这个配置默认不配呢
明明是挺重要的一个参数,这么不配迟早内存会用完的啊,仔细看了文档之后才明白,这个居然是刻意这么做的!
这个默认设置是刻意选择的:fielddata 不是临时缓存。它是驻留内存里的数据结构,必须可以快速执行访问,而且构建它的代价十分高昂。如果每个请求都重载数据,性能会十分糟糕。
这个设置是一个安全卫士,而非内存不足的解决方案。
如果没有足够空间可以将 fielddata 保留在内存中,Elasticsearch 就会时刻从磁盘重载数据,并回收其他数据以获得更多空间。内存的回收机制会导致重度磁盘I/O,并且在内存中生成很多垃圾,这些垃圾必须在晚些时候被回收掉。
说到底,还是需要资源把它堆起来,才能发挥最大的性能,之前查资料有看到过,要让 es 性能要好,最佳的情况下,就是你的机器的内存,至少可以容纳你的总数据量的一半。
当然,这个问题只在es 7.0版本之前存在,7.0之后会引入一种数据类型叫doc_values,用以解决这种es聚合带来的内存开销。
其核心的思想其实也很简单,原本的es存储结构为倒排索引,这个结构搜索快,但是要做聚合就只能全拿到内存去,7.0之后的版本就是给了个doc_values类型给你选择,标记为这种类型的数据会额外多存一份正排的索引,专门用于聚合查询。
关于倒排索引之前也有过一段研究,有时间再好好记录下来吧。